为什么你的AI修图总是不对劲?揭秘图像编辑评测的信任危机
你是否有这样的经历:让AI把照片里的白马换成鹿,结果出来的却是一匹棕色的马,旁边还多了一只不知道从哪冒出来的山羊?或者说,你明明只想要换个背景,AI却把人物的脸也悄悄美颜了一圈?这种"答非所问"的挫败感,几乎每个用过图像编辑AI的人都体验过。而问题的根源,往往不在AI不够聪明,而在于我们根本不知道该如何评价它。
评测失灵:看不见的信任危机
想象一下,你是一个产品经理,需要在三个图像编辑模型中选出最合适的那一个。翻翻各家的技术报告,你会发现一个有趣的现象:每个模型都说自己"表现优异",但数据来源、评测方法、评估维度全都不一样。有人用参考图像对比,有人让大模型打分,有人干脆请人工标注。你该怎么办?
这绝非个例,而是整个行业面临的系统性难题。传统评测方法的局限性体现在三个层面:第一,基于参考图像的评测覆盖场景有限,无法反映真实应用中的多样性需求;第二,基于大模型的评测缺乏空间感知,容易被细微的颜色变化误导;第三,缺乏统一的评测标准,导致横向比较几乎不可能。当企业无法准确评估模型能力时,技术迭代就会失去方向。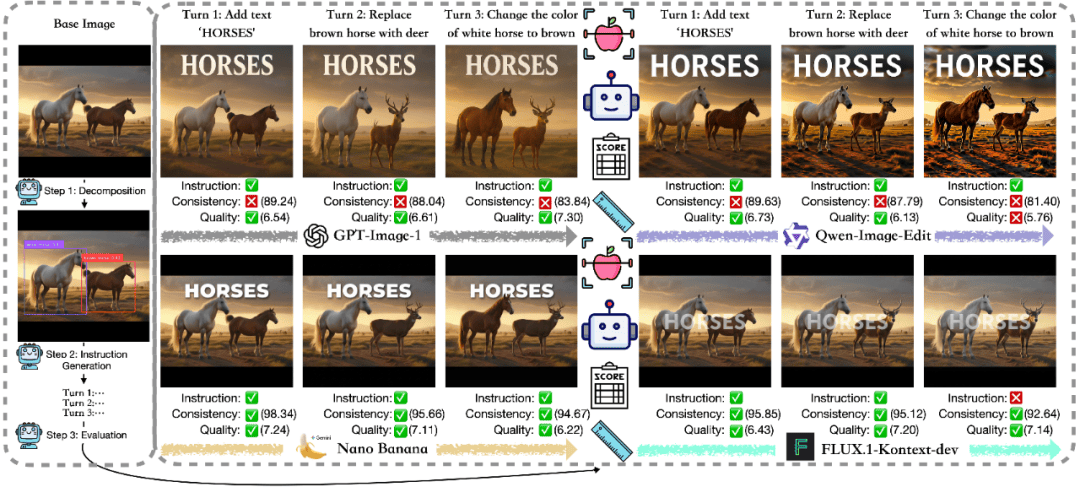
EdiVal-Agent破局:像人类一样看懂图像
来自得克萨斯大学奥斯汀分校、UCLA、微软等机构的研究者们在论文中分享了一个故事:他们在评测一款主流图像编辑模型时,发现模型对指令"把白马的毛色改成棕色"的执行结果与预期完全不符。模型确实完成了任务,但同时改变了背景中的树木颜色、人物的衣服颜色,甚至让照片整体变得更亮了。从"执行指令"的角度看,模型完成了任务;但从"保持一致性"的角度看,这是一个严重的失败。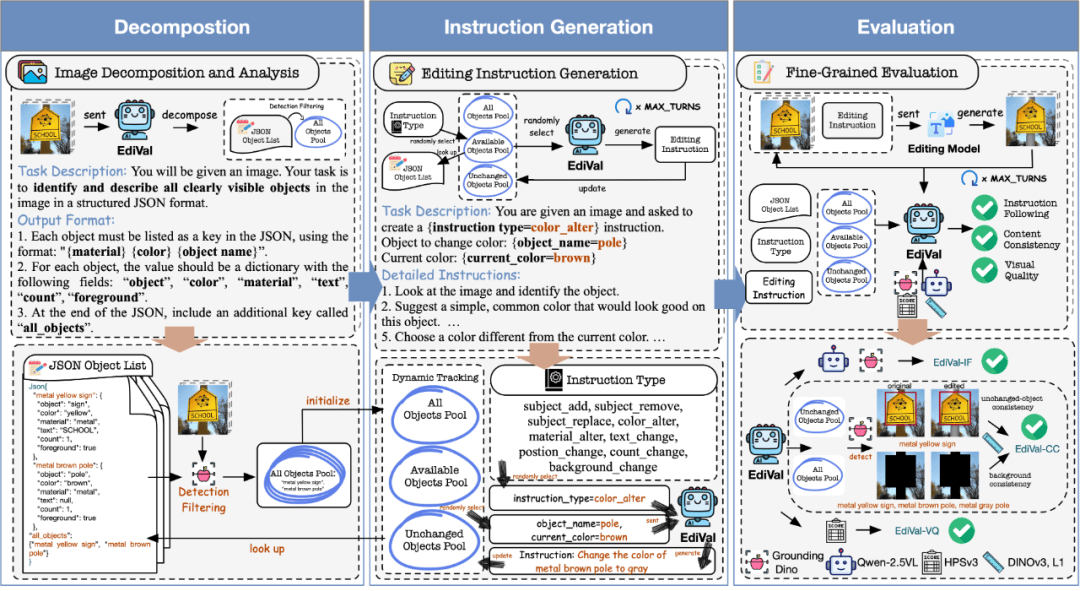
EdiVal-Agent的设计正是为了解决这个问题。它首先让AI"看懂"图像中的每个对象,理解它们之间的关系;然后生成多轮递进的编辑指令,测试模型在不同情境下的表现;最后从三个维度综合评估——指令遵循、内容一致性、视觉质量。这三个维度缺一不可:指令遵循看模型是否"听懂"了,内容一致性看模型是否"稳重",视觉质量看结果是否"好看"。
实战验证:谁才是真正的强者
研究团队设计了一个直观的测试场景:一张包含两匹马的图片,经过三轮编辑——先是添加文字"HORSES",然后把棕色马换成鹿,最后把白马的毛色改成棕色。听起来很简单,对吧?但各家模型的表现却大相径庭。GPT-Image-1执行指令没问题,但背景越来越不一致;Qwen-Image-Edit在第三轮后出现了明显的过曝感;FLUX.1-Kontext-dev能保留背景但指令理解有偏差;表现最稳定的是NanoBanana——稳、准、无明显短板。
在更大规模的13个模型横评中,Seedream4.0凭借出色的指令遵循能力全面超越国际闭源模型,排名第一;NanoBanana在速度与质量间达成完美平衡,内容一致性尤为突出;GPT-Image-1因为追求美观而牺牲了一致性,位列第三。这些结果背后有一个共同的规律:真正优秀的图像编辑模型,不是某一项指标突出,而是多个维度之间找到了恰到好处的平衡点。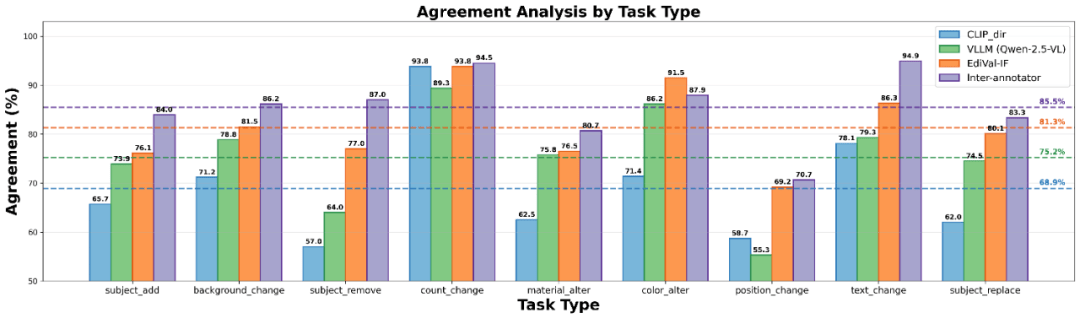
评测的意义:让技术进化有据可循
EdiVal-Agent的人类一致性验证揭示了一个更深层的洞察:这套系统与人类判断的一致率高达81.3%,已经非常接近人类评测员之间的85.5%。这意味着,评测不再是"自说自话",而是真正反映了用户的需求与期望。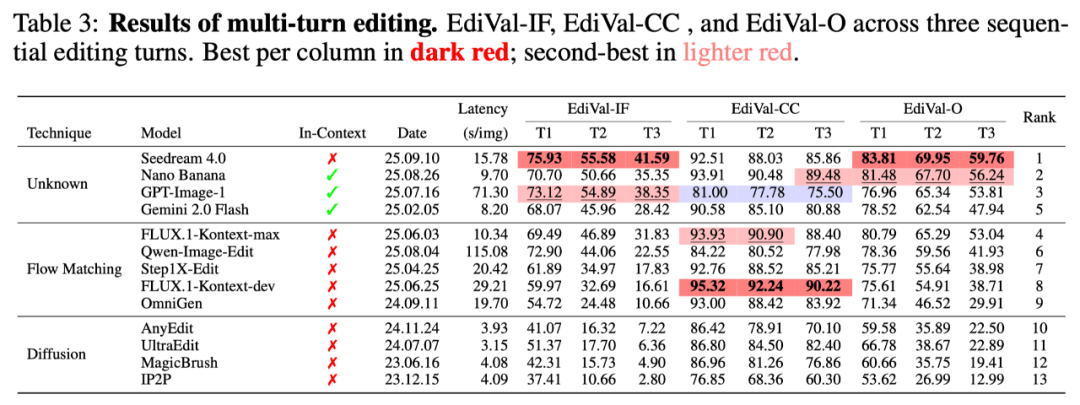
对于每一个正在使用或计划使用图像编辑AI的人来说,这个进步的意义在于:以后选择模型时,你可以不再依赖厂商的自我宣传,而是拥有了一套可信赖的评估工具。对于技术开发者而言,这意味着迭代方向更加清晰——哪里做得不够好,哪里需要改进,都有客观数据作为支撑。
图像编辑AI的下一个阶段,不只是让AI"能修图",而是让它"修对图"。而EdiVal-Agent,正是这条路上的一个重要里程碑。